
By Davood Shahabi
April 15, 2023
The Credit-Risk repository on GitHub by Davood contains a machine learning model to predict credit risk for a given set of customers.
The model is developed using Python and Jupyter Notebook and employs several machine learning algorithms, including logistic regression, decision tree, random forest, and gradient boosting. The dataset used in the model is from a bank and includes information such as age, income, loan amount, and credit history of customers.
The repository also includes a data cleaning script to preprocess the dataset and a detailed report explaining the methodology and results of the model. The code and report are well-documented and can serve as a useful reference for anyone interested in building a credit risk prediction model.
You can check out the code and details in Davood's GitHub directly. Below is an executive summary of the completed project.
Credit-Risk Project
The goal of the project is to predict the risk of financial failure based on historical data.
Banks and financial organizations use the historical data on customers' behaviour to predict the probability of future defaults of credit card borrowings.
Banks can use credit risk prediction to decide whether to issue a credit card to the applicant.
Data Sets
for this project, we have 2 different datasets:
- Application Records: all data related to the demographic information of applicants
- Credit Records: historical credit card status of each applicant
Applicant ID is a primary key to joining datasets.
Project Phases
The project was led in 2 major phases:
- Exploratory Data Analytics: 1) Data Cleaning, 2) Feature engineering
- Predictive modeling
Feature Engineering
A label indicating delinquency occurrences 3 months in advance can be generated by considering the account history and status of each individual account.

The dat set containes an imbalanced label:

Therefore, we applied under sampling technique for the model training.
Finally, the dataset was ready for modeling. Here is a sample of processed data:
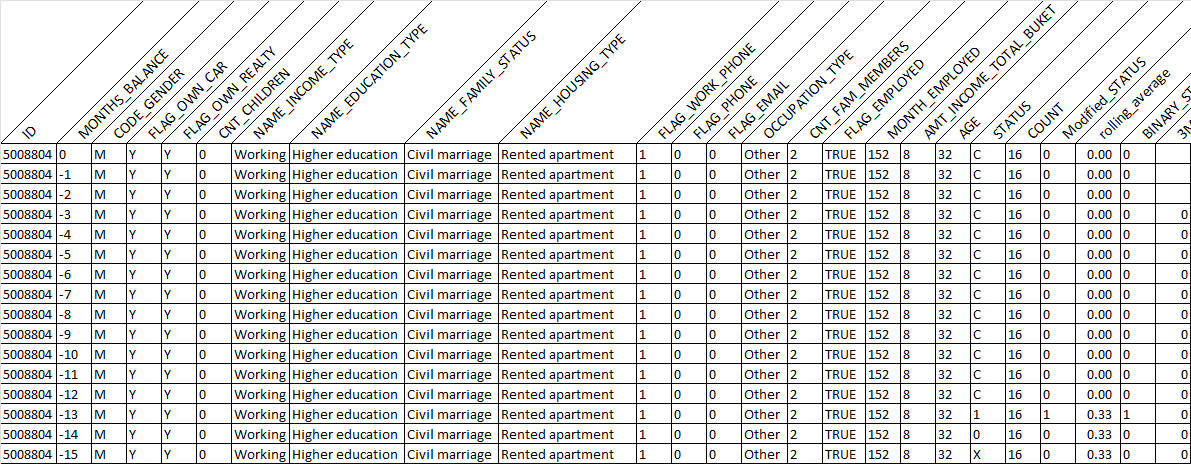
Based on the model, we may use onehot_encoding or other techniques for effective predictive model development.
Correlations
We performed a correlation analysis to assess the relationship between the features and the label prior to building the model:

The purpose of creating a correlation heatmap of features before developing predictive models is to understand the relationship between different features in a dataset. A correlation heatmap is a graphical representation of the correlation matrix that shows the correlation coefficients between each pair of features in a dataset. The correlation coefficient measures the strength and direction of the linear relationship between two variables. Creating a correlation heatmap before developing predictive models helps us to understand the relationship between features in a dataset and can guide us in making decisions about feature selection, model interpretation, and improving model performance.
Modeling
Developed 3 major predictive models:
- Random Forest
- XGBOOST
- CATBOOST
Results
The model metrics are saved in a table for a fast and clear comparison:
| NO |
Model |
accuracy_score |
precision_score |
recall_score |
roc_auc_score |
f1_score |
| 1 |
randomforest_Final |
0.864091 |
0.888571 |
0.678404 |
0.817851 |
0.769394 |
| 2 |
xgboost_model_fin |
0.781087 |
0.952576 |
0.363041 |
0.676985 |
0.525722 |
| 3 |
ctboost_model_fin |
0.867162 |
0.921760 |
0.658228 |
0.815100 |
0.768016 |
| <br> |
|
|
|
|
|
|
Catboost model has a better performance to predict high-risk applicants. Since we have an imbalanced data, the recall score can be an important metric for this project. Catboost has the highest precision and recall scores.

Davood Shahabi
Davood is one of the recent graduates from 1-on-1 Mentoring Program in OFallon Labs. This article is an overview of one of his Data Science project that he did in OLabs in early 2023.