By Saeed Mirshekari
June 9, 2023


Access O'Mentors
Top Data Scientist Mentors from Fortune 500 Companies excited to help you out 1-on-1!
1️⃣ Explore freely
→
2️⃣ Apply confidently
→
3️⃣ Pay securely
→
4️⃣ Book instantly
Introduction
Classification models play a vital role in today's data science world. However, understanding the inner workings of these models and interpreting their results can be challenging. This is where the Lime library comes to the rescue. In this blog post, we will explore how the Lime library can help explain the results of a classification model for wine quality prediction. By leveraging Lime's interpretability capabilities, you can gain valuable insights into the factors influencing AI models' predictions.
1. Understanding Lime and Interpretability
Lime (Local Interpretable Model-Agnostic Explanations) is a popular library used for model interpretability and explanation. It provides a framework for explaining individual predictions of machine learning models in a human-understandable manner. Lime works by approximating the behavior of the underlying model locally and providing explanations based on feature importance.
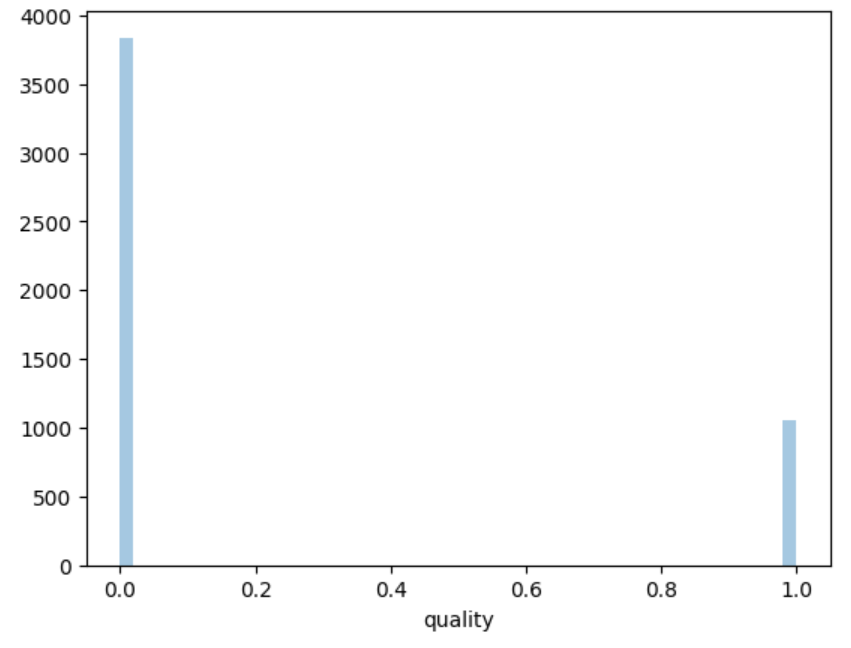
2. Preparing the Wine Quality Dataset
To demonstrate the use of Lime, we need a wine quality dataset. We'll start by obtaining a dataset that includes various characteristics of wines, such as acidity, pH level, alcohol content, and more. It should also include a quality rating for each wine. This dataset will serve as the foundation for training our classification model.
3. Building and Training the Classification Model
Using the wine quality dataset, we'll develop a classification model to predict wine quality based on the available characteristics. We can choose a suitable algorithm such as Random Forest, Support Vector Machines, or Neural Networks. Once trained, the model will be ready for prediction and explanation.
4. Explaining Wine Quality Predictions with Lime
Now comes the exciting part—using Lime to explain the predictions made by our classification model. Lime helps identify which features and their values contribute the most to a particular wine quality prediction. By generating explanations for individual predictions, we can gain a deeper understanding of how the model arrived at its decisions.
5. Visualizing Lime Explanations
Lime provides visualizations that make it easier to interpret the explanations. These visualizations can include bar charts, heatmaps, or other suitable representations that highlight the contribution of each feature to the prediction. Through visual exploration, we can uncover patterns and correlations between wine characteristics and quality.
Here are just two examples for you from "Good" wines and why Lime thinks the model have labeled them as "Good". The reasons make sense to me! :)
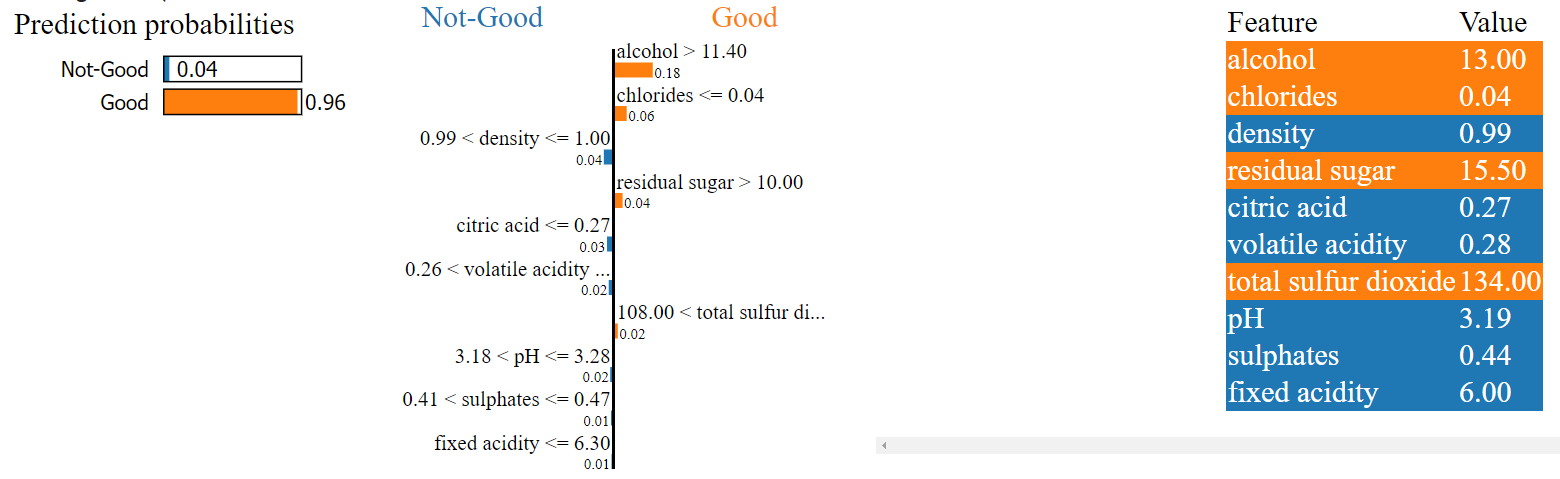

6. Interpreting and Validating the Explanations
Interpreting Lime explanations requires careful analysis and validation. It's important to consider the context and domain knowledge to ensure the explanations align with our expectations. Additionally, we can validate the explanations by comparing them with our own understanding of wine quality and expert opinions.
Conclusion
The Lime library offers a powerful tool for explaining the results of a classification model in wine quality prediction. By leveraging Lime's interpretability capabilities, we can gain insights into the factors influencing predictions, making the model's decisions more transparent and understandable. This knowledge empowers us to make informed decisions in the wine industry, enhance our models, and ultimately improve the quality of predictions.
Source Code

Saeed Mirshekari
Saeed is currently a Director of Data Science in Mastercard and the Founder / Director of OFallon Labs LLC. He is a former research scholar at LIGO team (Physics Nobel Prize of 2017).