
By Saeed Mirshekari
September 4, 2023
Understanding Cost Functions and Measuring Classification Model Performance
In the realm of data science and machine learning, classification problems are ubiquitous. Whether it's spam email detection, disease diagnosis, or sentiment analysis, the ability to build and evaluate classification models is fundamental. To gauge the effectiveness of these models, we turn to cost functions and performance metrics. In this in-depth exploration, we'll dive into the world of cost functions and various techniques to measure the performance of classification models. Whether you're a budding data scientist or a seasoned enthusiast, this guide will equip you with the tools you need.
Table of Contents
- What Are Cost Functions?
- The Importance of Cost Functions
- Performance Metrics for Classification
- Confusion Matrix
- Accuracy
- Precision and Recall
- F1-Score
- ROC Curve and AUC
- Implementing in Python
- Conclusion
What Are Cost Functions?
Before we delve into performance metrics, let's understand the concept of cost functions. In the context of classification, a cost function is a mathematical function that quantifies the "cost" associated with the model's predictions. It helps us measure how well our model is performing by evaluating how far off its predictions are from the actual values.
In classification, the most commonly used cost function is the cross-entropy loss (also known as log loss). The cross-entropy loss measures the dissimilarity between the predicted probability distribution and the actual class distribution. It's particularly suited for binary and multiclass classification problems.
Mathematically, for binary classification, the cross-entropy loss can be defined as:
\begin{equation}
J(y, \hat{y}) = -\frac{1}{m} \sum_{i=1}^{m} \left[y_i \log(\hat{y}_i) + (1 - y_i) \log(1 - \hat{y}_i)\right]
\end{equation}
Where:
$y_i$ is the true label (0 or 1) for the i-th example.$\hat{y}_i$ is the predicted probability that the i-th example belongs to class 1.$m$ is the number of examples in the dataset.
The goal is to minimize this loss function during the training of a classification model.
The Importance of Cost Functions
Cost functions serve as the foundation for building robust classification models. Here's why they are essential:
1. Model Training
Cost functions are crucial during the training phase. Machine learning algorithms aim to find model parameters that minimize the cost function, effectively aligning the model's predictions with the true labels in the training data.
2. Model Evaluation
Cost functions provide a quantitative measure of how well a model is performing. By calculating the cost on a separate validation or test dataset, you can assess the model's generalization ability.
3. Hyperparameter Tuning
In hyperparameter optimization, cost functions help you select the best set of hyperparameters for your model. You can experiment with different configurations and choose the one that results in the lowest cost.
Now that we understand the role of cost functions, let's explore performance metrics that help us interpret these costs effectively.
Performance Metrics for Classification
Measuring the performance of a classification model involves more than just looking at the cost function. A range of performance metrics provides a comprehensive view of how well the model is doing. Let's delve into these metrics:
Confusion Matrix
The confusion matrix is a fundamental tool for understanding classification performance. It provides a tabular representation of actual versus predicted class labels. It consists of four values:
- True Positives (TP): The number of instances correctly predicted as positive.
- True Negatives (TN): The number of instances correctly predicted as negative.
- False Positives (FP): The number of instances incorrectly predicted as positive (Type I error).
- False Negatives (FN): The number of instances incorrectly predicted as negative (Type II error).
Here's a visual representation:
Predicted Positive Predicted Negative
Actual Positive TP FN
Actual Negative FP TN
Accuracy
Accuracy is perhaps the most straightforward performance metric. It calculates the proportion of correct predictions over the total number of predictions.
\begin{equation}
\text{Accuracy} = \frac{TP + TN}{TP + FP + FN + TN}
\end{equation}
While accuracy is easy to understand, it can be misleading when dealing with imbalanced datasets, where one class is significantly more prevalent than the other.
Precision and Recall
Precision and recall provide more nuanced insights into classification performance:
- Precision measures the proportion of true positive predictions among all positive predictions. It focuses on minimizing false positives.
\begin{equation}
\text{Precision} = \frac{TP}{TP + FP}
\end{equation}
- Recall (also known as sensitivity or true positive rate) measures the proportion of true positive predictions among all actual positives. It focuses on minimizing false negatives.
\begin{equation}
\text{Recall} = \frac{TP}{TP + FN}
\end{equation}
Precision and recall are particularly important in scenarios where false positives and false negatives have different consequences. For example, in medical diagnosis, missing a true positive (low recall) can be more detrimental than incorrectly identifying a healthy person as sick (low precision).
F1-Score
The F1-Score is the harmonic mean of precision and recall. It balances the trade-off between precision and recall, providing a single metric that considers both false positives and false negatives.
\begin{equation}
\text{F1-Score} = \frac{2 \cdot \text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}}
\end{equation}
The F1-Score is particularly useful when you want a single metric that captures the overall classification performance.
ROC Curve and AUC
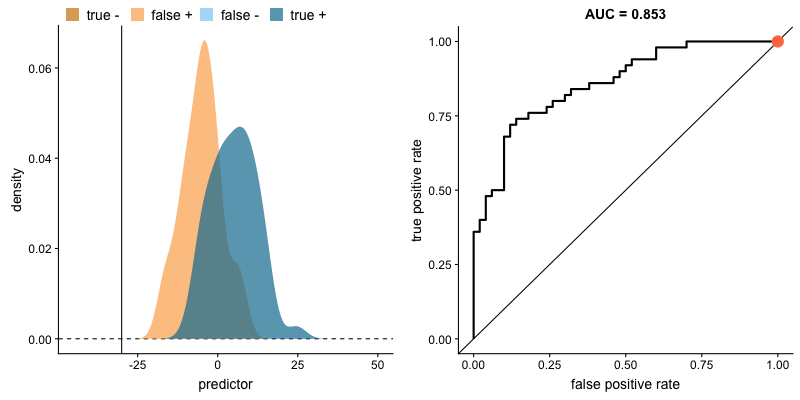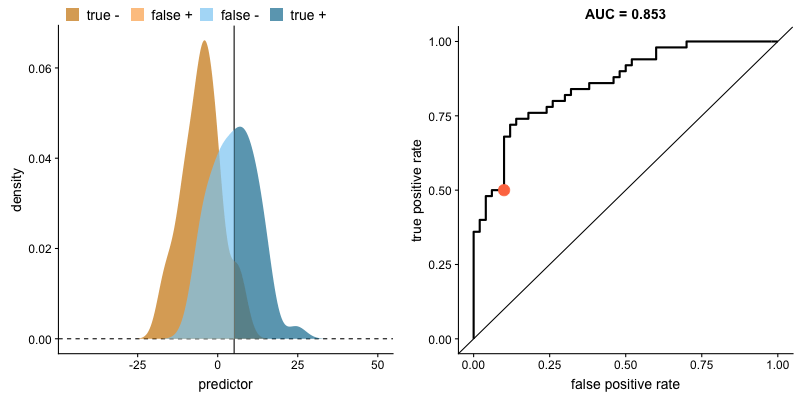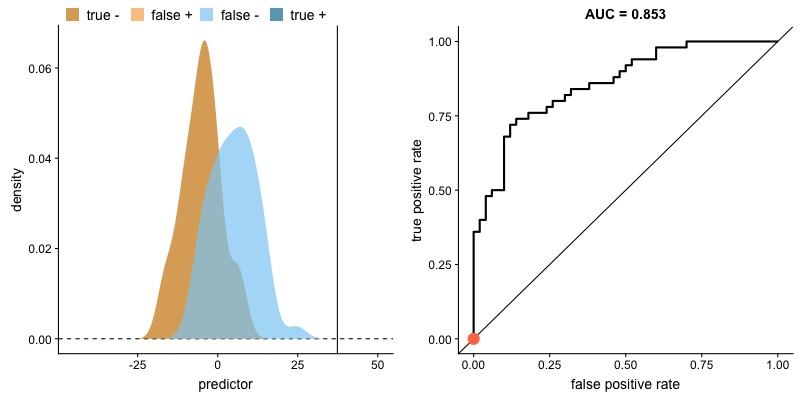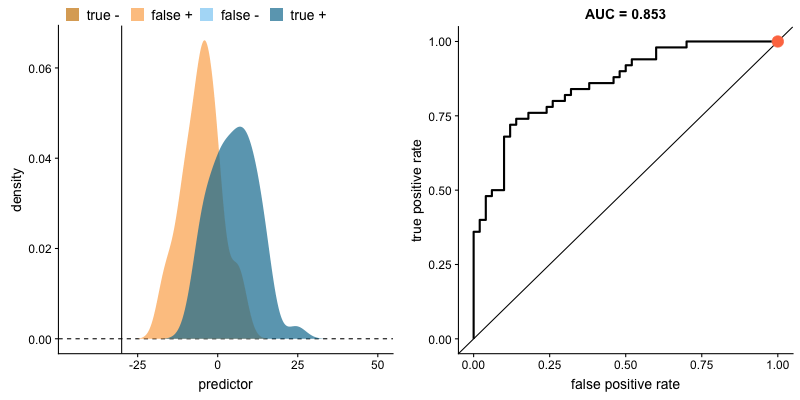
The Receiver Operating Characteristic (ROC) curve is a graphical representation of a classifier's performance across different thresholds. It plots the true positive rate (recall) against the false positive rate as the decision threshold varies.
The Area Under the Curve (AUC) of the ROC curve quantifies the model's ability to distinguish between positive and negative classes. A higher AUC indicates better performance.
Implementing in Python
Let's put theory into practice by implementing these performance metrics in Python. We'll use the scikit-learn library to create a simple classification example and calculate these metrics.
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score, roc_curve, auc
import matplotlib.pyplot as plt
# Generate synthetic data
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train a logistic regression model
model = LogisticRegression()
model.fit(X_train, y_train)
# Make predictions on the test set
y_pred = model.predict(X_test)
y_prob = model.predict_proba(X_test)[:, 1]
# Calculate confusion matrix
conf_matrix = confusion_matrix(y_test, y_pred)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
# Calculate precision
precision = precision_score
(y_test, y_pred)
# Calculate recall
recall = recall_score(y_test, y_pred)
# Calculate F1-Score
f1 = f1_score(y_test, y_pred)
# Calculate ROC curve and AUC
fpr, tpr, thresholds = roc_curve(y_test, y_prob)
roc_auc = auc(fpr, tpr)
# Plot ROC curve
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC)')
plt.legend(loc='lower right')
plt.show()
# Print results
print(f'Confusion Matrix:\n{conf_matrix}')
print(f'Accuracy: {accuracy:.2f}')
print(f'Precision: {precision:.2f}')
print(f'Recall: {recall:.2f}')
print(f'F1-Score: {f1:.2f}')
print(f'AUC: {roc_auc:.2f}')
This example demonstrates how to calculate and visualize various performance metrics for a classification model using scikit-learn.
Conclusion
In the world of data science, building and evaluating classification models is a fundamental task. Cost functions, such as the cross-entropy loss, guide the training process by quantifying the "cost" of model predictions. However, to truly understand a model's performance, a range of performance metrics, including accuracy, precision, recall, F1-score, ROC curve, and AUC, are essential.
Each metric provides unique insights into a model's strengths and weaknesses. Precision and recall, for instance, are vital when dealing with imbalanced datasets or scenarios where false positives and false negatives carry different consequences.
As a data science enthusiast or junior data scientist, mastering these metrics will empower you to build and evaluate classification models effectively. Remember that the choice of metric depends on the specific problem you're tackling, and a combination of metrics often provides a more comprehensive view of your model's performance. So, dive in, experiment, and use these tools to make informed decisions about your classification models.