By Saeed Mirshekari
September 4, 2023
Understanding Cost Functions and Evaluating Regression Model Performance
Regression analysis is a fundamental tool in the data scientist's toolbox. It allows us to understand and make predictions based on relationships between variables. But how do we measure the performance of a regression model? In this comprehensive guide, we'll explore cost functions and various techniques to assess the effectiveness of regression models. Whether you're an aspiring data scientist or a junior practitioner, this article will equip you with the knowledge you need to excel in regression analysis.
Table of Contents
- What Are Cost Functions in Regression?
- The Role of Cost Functions
- Performance Metrics for Regression
- Mean Absolute Error (MAE)
- Mean Squared Error (MSE)
- Root Mean Squared Error (RMSE)
- R-squared (R2)
- Adjusted R-squared
- Implementing in Python
- Conclusion
What Are Cost Functions in Regression?
Before diving into the world of performance metrics, let's understand what cost functions are in the context of regression. A cost function (also known as a loss function) is a mathematical function that quantifies the disparity between the predicted values of a regression model and the actual observed values (the ground truth).
In regression, the most commonly used cost function is the mean squared error (MSE). It calculates the average of the squared differences between predicted and actual values:
\begin{equation}
MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2
\end{equation}
Where:
$y_i$ is the actual value for the i-th observation.$\hat{y}_i$ is the predicted value for the i-th observation$n$ is the total number of observations.
The goal during training is to minimize the MSE, effectively making the model's predictions as close as possible to the actual values.
The Role of Cost Functions
Cost functions play a pivotal role in regression for several reasons:
1. Model Training
During the training phase of a regression model, cost functions help optimize the model's parameters. The objective is to find the parameter values that minimize the cost function, aligning the model's predictions with the actual data.
2. Model Evaluation
Cost functions are essential for evaluating a regression model's performance. By comparing the model's predictions to a test dataset or unseen data, you can assess how well the model generalizes to new observations.
3. Hyperparameter Tuning
When tuning hyperparameters or choosing between different regression algorithms, cost functions help you make informed decisions. You can experiment with various settings and select the ones that lead to the lowest cost.
Now that we've grasped the concept of cost functions, let's explore performance metrics that provide a comprehensive view of regression model performance.
Performance Metrics for Regression
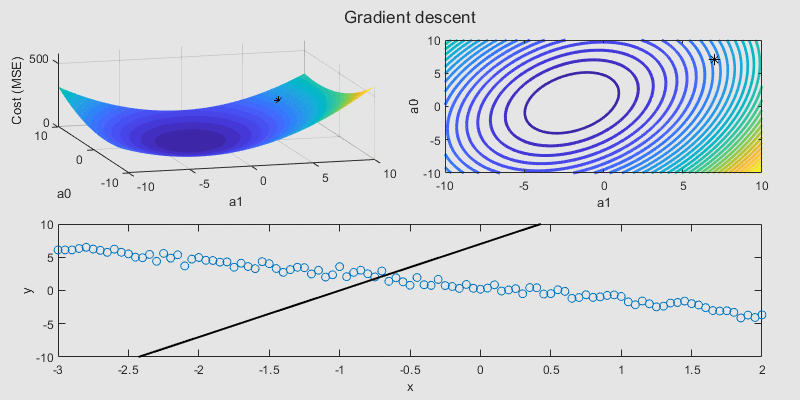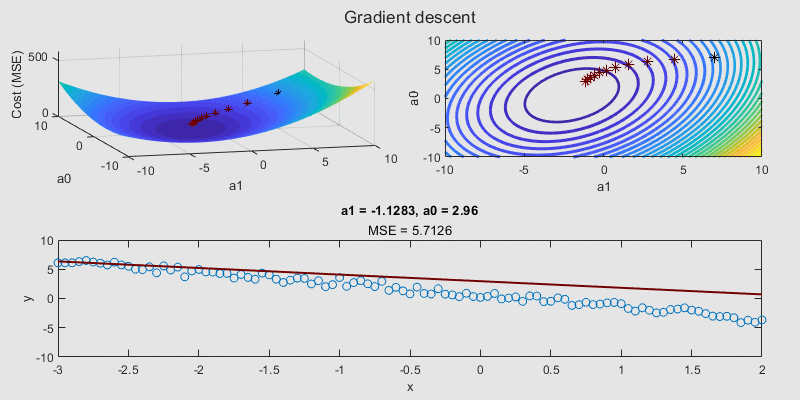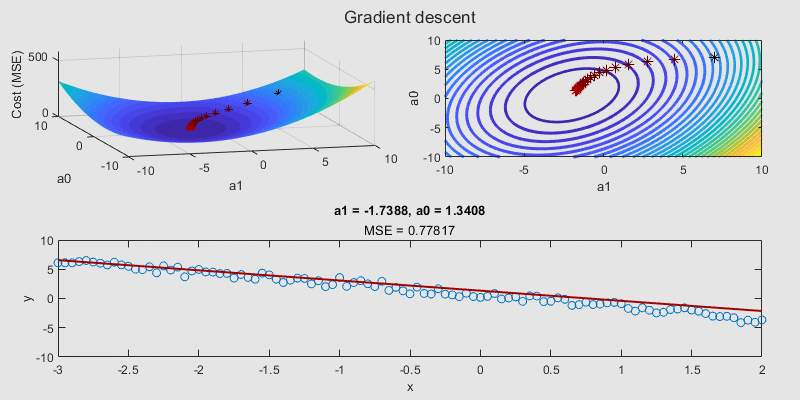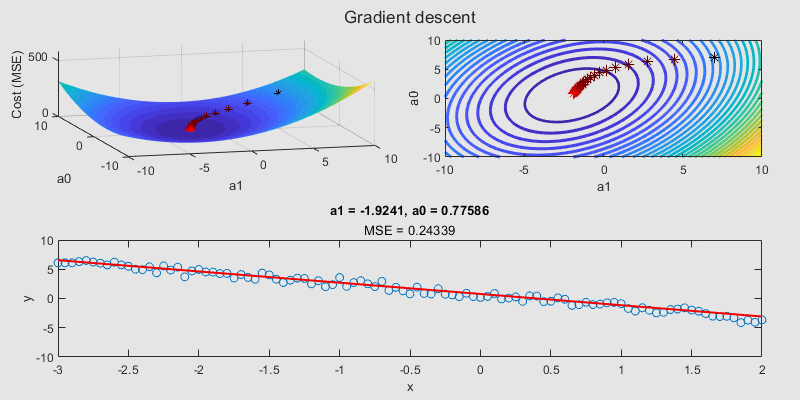
Assessing the performance of a regression model involves more than just looking at the cost function. A variety of performance metrics help us interpret the model's predictions effectively. Let's delve into these metrics:
Mean Absolute Error (MAE)
Mean Absolute Error (MAE) calculates the average of the absolute differences between predicted and actual values:
\begin{equation}
MAE = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i|
\end{equation}
MAE is easy to interpret, as it represents the average magnitude of errors. A lower MAE indicates better model performance.
Mean Squared Error (MSE)
We've already discussed MSE as a cost function, but it's also a common performance metric. While it squares errors, making it sensitive to outliers, it provides a measure of the variance in prediction errors:
\begin{equation}
MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2
\end{equation}
MSE is widely used due to its mathematical properties and suitability for optimization.
Root Mean Squared Error (RMSE)
RMSE is the square root of the MSE and shares the same unit as the target variable. It provides a measure of the standard deviation of prediction errors:
\begin{equation}
RMSE = \sqrt{MSE}
\end{equation}
RMSE is preferred when you want the performance metric to be in the same unit as the target variable.
R-squared (R2)
R-squared, also known as the coefficient of determination, quantifies the proportion of the variance in the dependent variable (target) that is predictable from the independent variables (features). It ranges from 0 to 1, with higher values indicating better model fit:
\begin{equation}
R^2 = 1 - \frac{SSR}{SST}
\end{equation}
Where:
$SSR$ is the sum of squared residuals (prediction errors).$SST$ is the total sum of squares, a measure of the variance in the target variable.
R-squared values closer to 1 suggest that the model explains a significant portion of the variance in the target variable, while values closer to 0 indicate poor model fit.
Adjusted R-squared
Adjusted R-squared is a modification of R-squared that accounts for the number of predictors in the model. It penalizes the addition of unnecessary variables and helps prevent overfitting:
\begin{equation}
Adjusted\ R^2 = 1 - \frac{(1 - R^2)(n - 1)}{n - p - 1}
\end{equation}
Where:
$n$ is the number of observations.$p$ is the number of predictors (independent variables).
Adjusted R-squared tends to be lower than R-squared when additional variables do not improve the model significantly.
Implementing in Python
Let's put theory into practice by implementing these performance metrics in Python. We'll use a simple linear regression example and calculate these metrics using the scikit-learn library.
import numpy as np
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score, mean_squared_log_error
import matplotlib.pyplot as plt
# Generate synthetic data
X, y = make_regression(n_samples=100, n_features=1, noise=0.1, random_state=42)
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train a linear regression model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions on the test set
y_pred = model.predict(X_test)
# Calculate MAE, MSE, RMSE, R-squared
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
# Print results
print(f'MAE: {mae:.2f}')
print(f'MSE: {mse:.2f}')
print(f'RMSE: {rmse:.2f}')
print(f'R-squared: {r2:.2f}')
This example demonstrates how to calculate and interpret various performance metrics for a regression model using scikit-learn.
Conclusion
In the realm of data science, regression analysis is a powerful technique for understanding and predicting relationships between variables. To assess the quality
of regression models, cost functions and performance metrics play a pivotal role.
Cost functions like MSE guide the training process, helping models minimize prediction errors. However, to truly understand a model's performance, a range of performance metrics—such as MAE, MSE, RMSE, R-squared, and adjusted R-squared—are essential.
Each metric offers unique insights into a model's strengths and weaknesses. MAE and RMSE provide measures of prediction accuracy, while R-squared and adjusted R-squared assess the model's overall fit and explainability.
Aspiring data scientists and junior practitioners can leverage these tools to build, evaluate, and fine-tune regression models effectively. Remember that the choice of metric depends on the specific problem you're tackling, and a combination of metrics often provides a more comprehensive view of your model's performance. So, dive in, experiment, and use these techniques to make informed decisions about your regression analyses.